
1. 技术核心框架解析
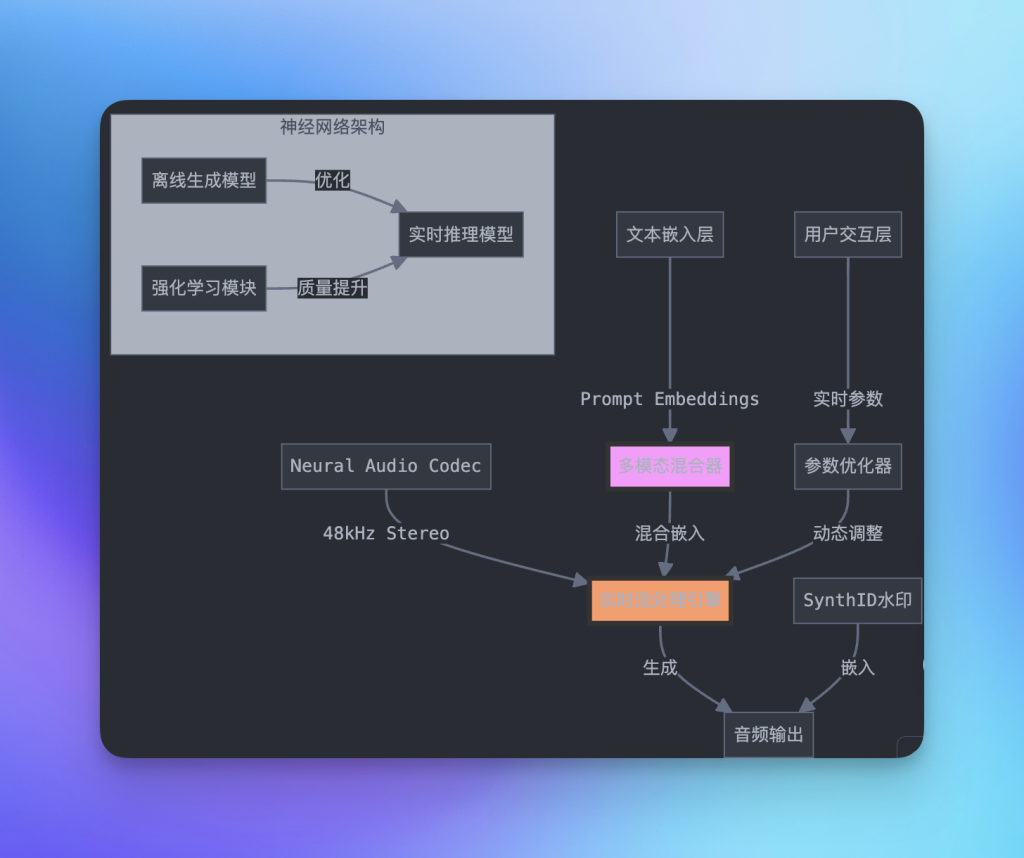
1.1 神经音频编解码器(Neural Audio Codec)• 实现高保真音频:支持48kHz立体声音频流式处理,并以低延迟实现高效生成。
• 定制化压缩算法:通过专有的音频压缩技术保障音质与实时性。
1.2 多模态提示词处理系统• 嵌入表示:将文本提示转化为高维嵌入向量,支持多维度语义表达。
• 动态混合机制:通过权重调整优化风格向量组合,生成更符合需求的音频内容。
1.3 实时生成架构该架构通过流式生成技术,将模型适配实时音频场景:
# 简化的模型架构示例
class MusicGenerationModel:
def __init__(self):
self.audio_codec = NeuralAudioCodec(sample_rate=48000)
self.embedding_mixer = PromptEmbeddingMixer()
self.stream_generator = StreamingGenerator()
def generate_stream(self, prompts, previous_audio):
# 混合多个提示词嵌入
mixed_embedding = self.embedding_mixer.mix(prompts)
# 条件音频生成
next_audio = self.stream_generator(
embedding=mixed_embedding,
context=previous_audio
)
# 音频编码和水印
processed_audio = self.audio_codec.encode(next_audio)
return SynthID.apply(processed_audio)2. 技术创新要点
2.1 实时音频生成突破
• 离线到实时适配:优化推理延迟与连续流生成能力,实现动态上下文处理。
• 实时风格转换:通过语义建模,生成个性化音乐风格。
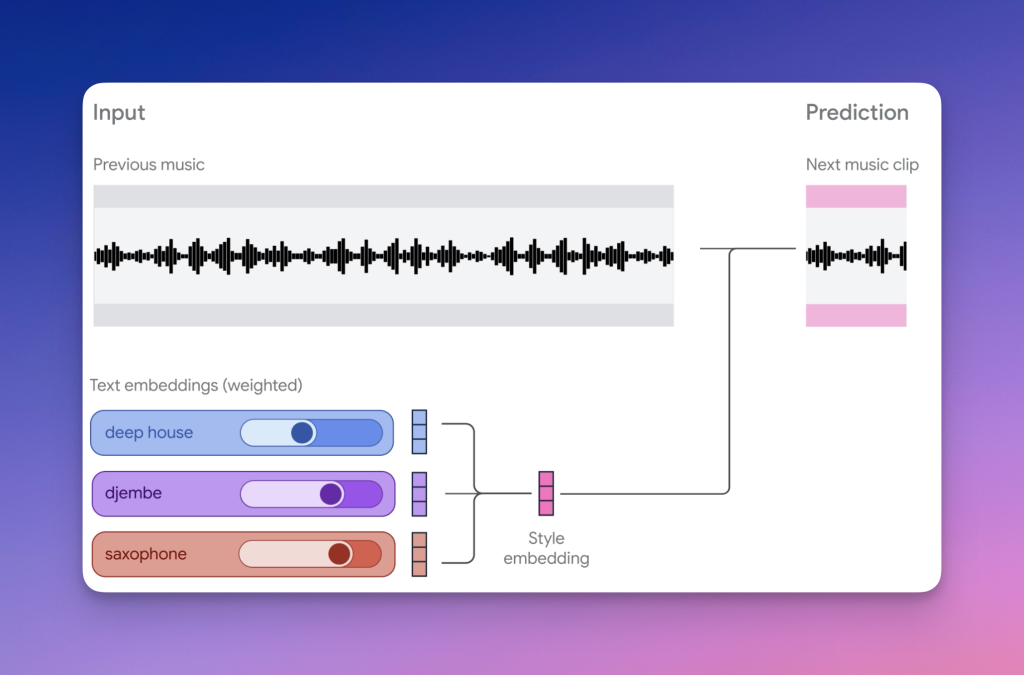
2.2 多重提示词处理技术
• 风格向量插值:嵌入空间中动态调整提示权重,实现风格的平滑过渡。
• 文本理解优化:提升提示词到音频的生成准确性。
2.3 强化学习驱动优化
• 文本到音频映射:通过新型强化学习算法优化模型响应,提高音频生成质量。
3. 专业功能模块
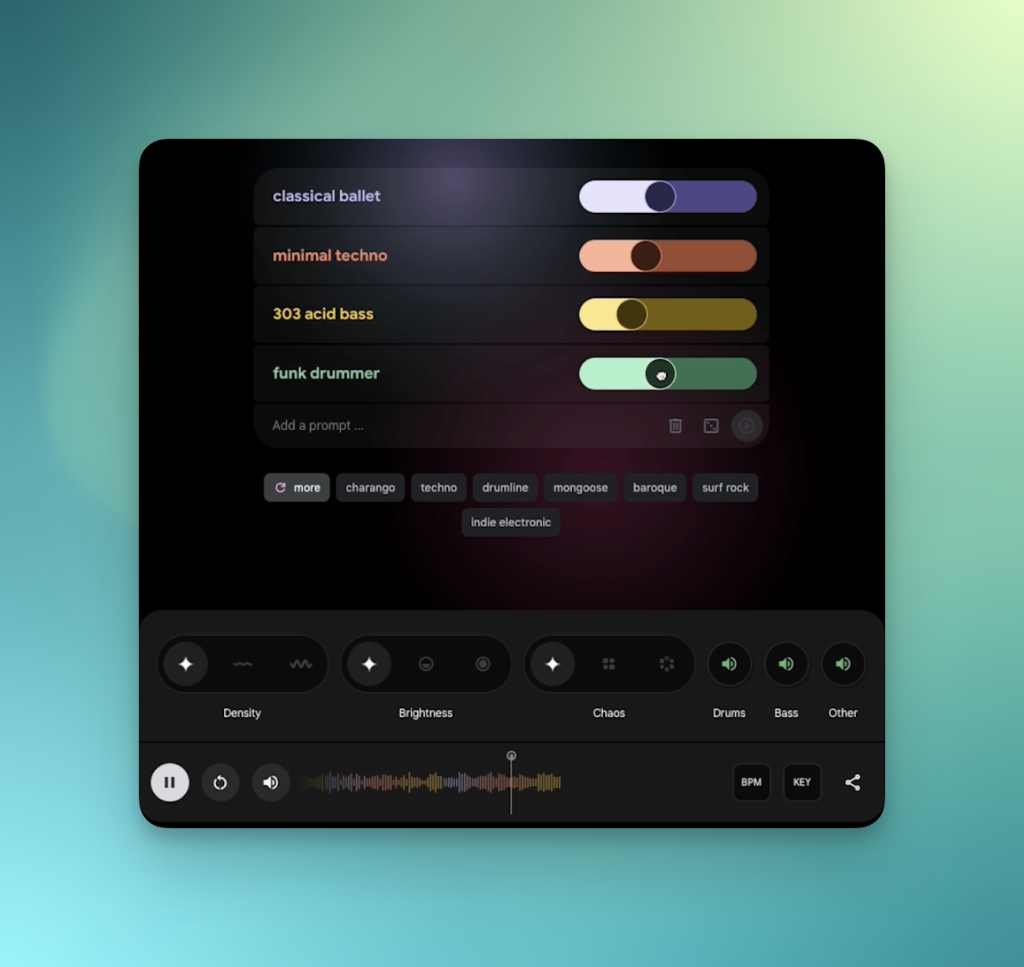
3.1 MusicFX DJ 核心功能
• 实时动态混音:支持多轨音频流的无缝衔接与实时效果器处理。
• 高级接口支持:提供参数化控制与实时频谱分析工具。
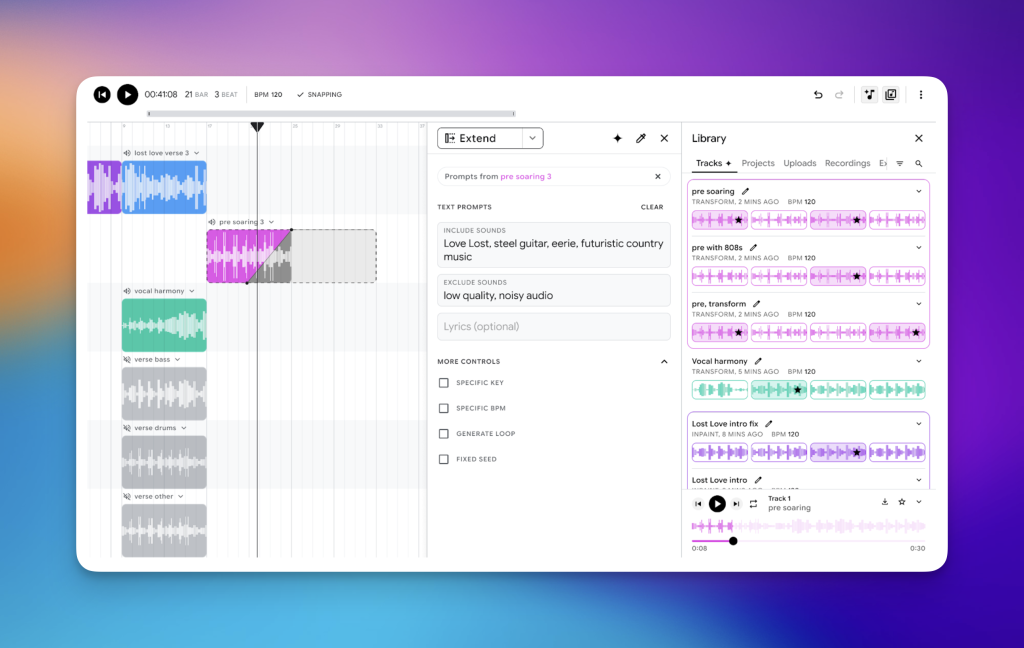
3.2 Music AI Sandbox 专业工具集
• 多轨编辑能力:支持音频修复、循环生成与和声分析,集成MIDI控制。
4. 技术安全与版权保护
4.1 SynthID 音频水印通过不可感知的水印技术,实现版权追踪与防篡改保护。
4.2 安全措施• 行为约束:对生成内容进行严格过滤,防止不当使用。
• 权限管理:确保技术用于合法场景。
5. 应用场景深度解析
5.1 专业音乐制作
• 创作辅助:提供和声生成、风格转换和编曲建议。
• 后期优化:支持音频混音与母带处理。
5.2 内容创作平台集成
• 社交媒体嵌入:例如YouTube Shorts可实时生成版权音乐替代方案。
6. 未来技术展望
6.1 模型优化方向
• 计算效率提升:在保持高质量生成的同时降低资源消耗。
• 维度扩展:支持更丰富的控制选项与复杂场景生成。
6.2 产品发展路线
• 专业版本迭代:针对音乐制作团队优化工具集。
• 跨平台支持:提供多平台SDK与API集成。
总结
DeepMind 的音乐生成式 AI 技术已成为深度学习在音频领域的标杆,其技术创新不仅推动了实时生成和多模态交互的发展,还显著降低了音乐创作门槛。未来,随着模型优化和功能拓展,该技术将在音乐产业的数字化转型中发挥更大的作用。
参考资料:New generative AI tools open the doors of music creation GenMedia music team
 using WordPress and
using WordPress and
No responses yet