Abstract
As Large Language Models (LLMs) increasingly infiltrate content generation workflows, the detection of machine-revised text—where LLMs refine or enhance human-authored content—has emerged as a critical frontier. While traditional approaches effectively identify purely machine-generated text, they falter when human contributions obscure the characteristic patterns of LLM output. This paper introduces the Imitate Before Detect (ImBD) framework, a groundbreaking methodology that aligns machine stylistic preferences with a probabilistic detection mechanism to address this challenge. ImBD not only redefines detection paradigms but also sets a benchmark for efficiency, requiring minimal computational resources while outperforming state-of-the-art alternatives.
Introduction
The democratization of advanced LLMs like GPT-4o has revolutionized text generation, fostering their adoption across academia, media, and enterprise content creation. However, this proliferation has raised significant ethical and operational concerns, particularly in the realms of academic integrity, misinformation, and automated plagiarism. Unlike pure machine-generated text, machine-revised text blurs the line between human-authored and LLM-modified content, posing unique challenges for detection systems.
Traditional detection methodologies, including logit-based metrics and supervised models, primarily target fully machine-generated texts. Yet, the nuanced stylistic interplay in machine-revised text—subtle shifts in token distribution, syntactic complexity, and lexical selection—renders these approaches inadequate. This paper introduces the ImBD framework, an innovative solution designed to identify machine-revised text by aligning detection models with LLM-generated stylistic preferences.

Methodology
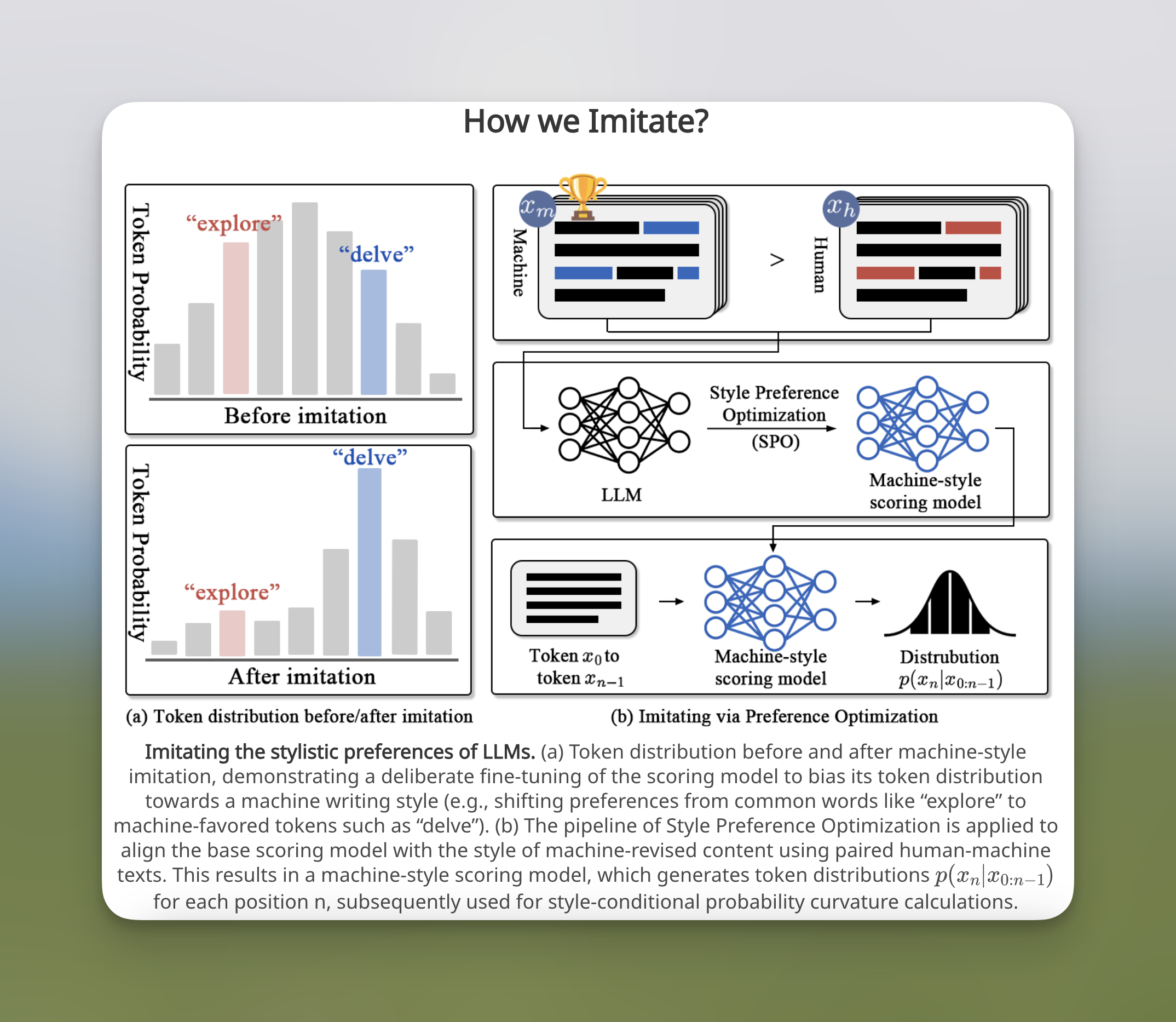
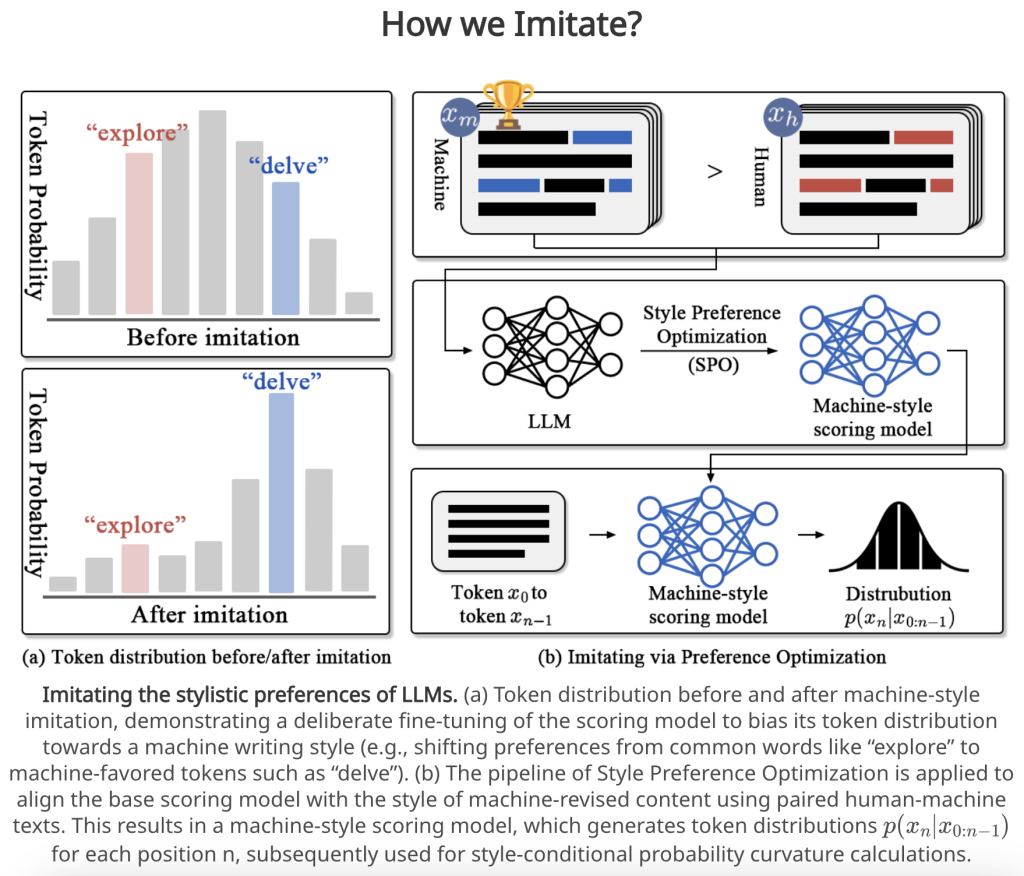
1. Style Preference Optimization (SPO)
At the core of ImBD lies Style Preference Optimization (SPO), a mechanism designed to mimic the stylistic patterns favored by LLMs. Through preference-based fine-tuning, the scoring model learns to distinguish between human and machine styles, isolating key stylistic signatures such as:
• Lexical Selection: Machine-preferred terms like “delve” and “intricate”.
• Structural Complexity: Increased use of subordinate clauses and consistent paragraph organization.
• Stylistic Regularity: Uniform tone and vocabulary patterns indicative of LLM influence.
By leveraging paired datasets of human-written and machine-revised texts with identical content, SPO trains the scoring model to systematically favor machine-style patterns over human-authored ones.
2. Style-Conditional Probability Curvature (Style-CPC)
To quantify stylistic alignment, ImBD introduces the Style-Conditional Probability Curvature (Style-CPC), a probabilistic metric that measures the divergence between human and machine stylistic distributions.
• Key Metric: Style-CPC evaluates the discrepancy in log probabilities between an original text and conditionally sampled alternatives, enabling fine-grained stylistic discrimination.
• Impact: By reducing distributional overlap, Style-CPC achieves a marked improvement in detection accuracy, even for advanced LLMs like GPT-4o.
Experimental Validation
Datasets
The evaluation leverages diverse datasets encompassing multiple domains:
• Human-written texts: Sourced from Wikipedia, PubMed, and creative writing forums, representing authentic human contributions.
• Machine-revised texts: Generated through structured pipelines using LLMs (GPT-3.5, GPT-4o, LLaMA-3) across revision tasks, including rewriting, expansion, and polishing.
Benchmarks and Comparisons
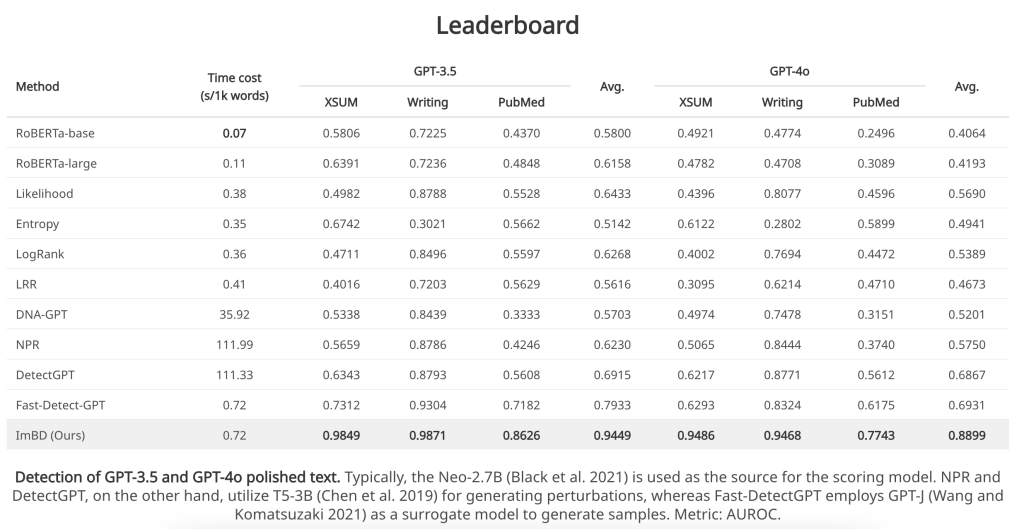
ImBD was rigorously benchmarked against state-of-the-art methods, including Fast-DetectGPT and GPTZero. The results underscore its superiority:
• GPT-3.5 Detection: 19.68% improvement in Area Under the ROC Curve (AUROC) compared to Fast-DetectGPT.
• Open-Source Models: Outperformed competing methods by an average of 25.79% in detecting machine-revised content.
• Efficiency: Achieved equivalent inference times (0.72s per 1,000 words) to Fast-DetectGPT while requiring 1/154th of the computational overhead.
Results and Discussion
1. Performance Insights
ImBD consistently outperformed baseline models across all evaluation metrics:
• Precision and Recall: Demonstrated robust sensitivity to subtle stylistic variations in machine-revised text.
• Generalizability: Maintained high accuracy across diverse text types, LLMs, and revision styles.
2. Scalability and Adaptability
• Resource Efficiency: Minimal training requirements (1,000 samples and five minutes of SPO) make ImBD highly scalable for real-world applications.
• Versatility: Effective across tasks such as rewrite, polish, and expand, with broad applicability in academia, media, and regulatory contexts.
Strengths and Limitations
Strengths
1. Innovative Approach: The paradigm shift from content-focused to style-focused detection.
2. High Efficiency: Exceptional performance with minimal computational resources.
3. Robust Generalization: Applicability across multiple domains, tasks, and LLMs.
Limitations
1. Domain Dependency: Potential sensitivity to domain-specific training data distributions.
2. Limited Multilingual Scope: Further research is required to adapt ImBD for non-English texts.
Conclusion
The ImBD framework represents a transformative advancement in detecting machine-revised text. By aligning detection models with machine stylistic preferences and leveraging probabilistic metrics, ImBD addresses the nuanced challenges posed by LLM-enhanced content. Its efficiency, adaptability, and superior performance establish a new benchmark for AI-assisted content detection, paving the way for responsible LLM deployment across industries.
Future Directions: Integrating multilingual support, expanding domain-specific capabilities, and exploring hybrid content scenarios will further enhance the applicability of this paradigm.
This work underscores the need for vigilance and innovation in AI governance, ensuring the integrity and authenticity of digital content in an era dominated by LLMs.
Refer & via:
- https://arxiv.org/pdf/2412.10432
- https://machine-text-detection.github.io/ImBD/

