1. 概述
SimpleQA是由OpenAI开发的一个新型基准测试集,专门用于评估大语言模型(LLMs)在回答简短、事实性问题时的表现。该测试集包含4,326个精心设计的问题,每个问题都经过严格验证,确保只有一个无争议的标准答案。
2. 数据集特征分析
2.1 主题分布
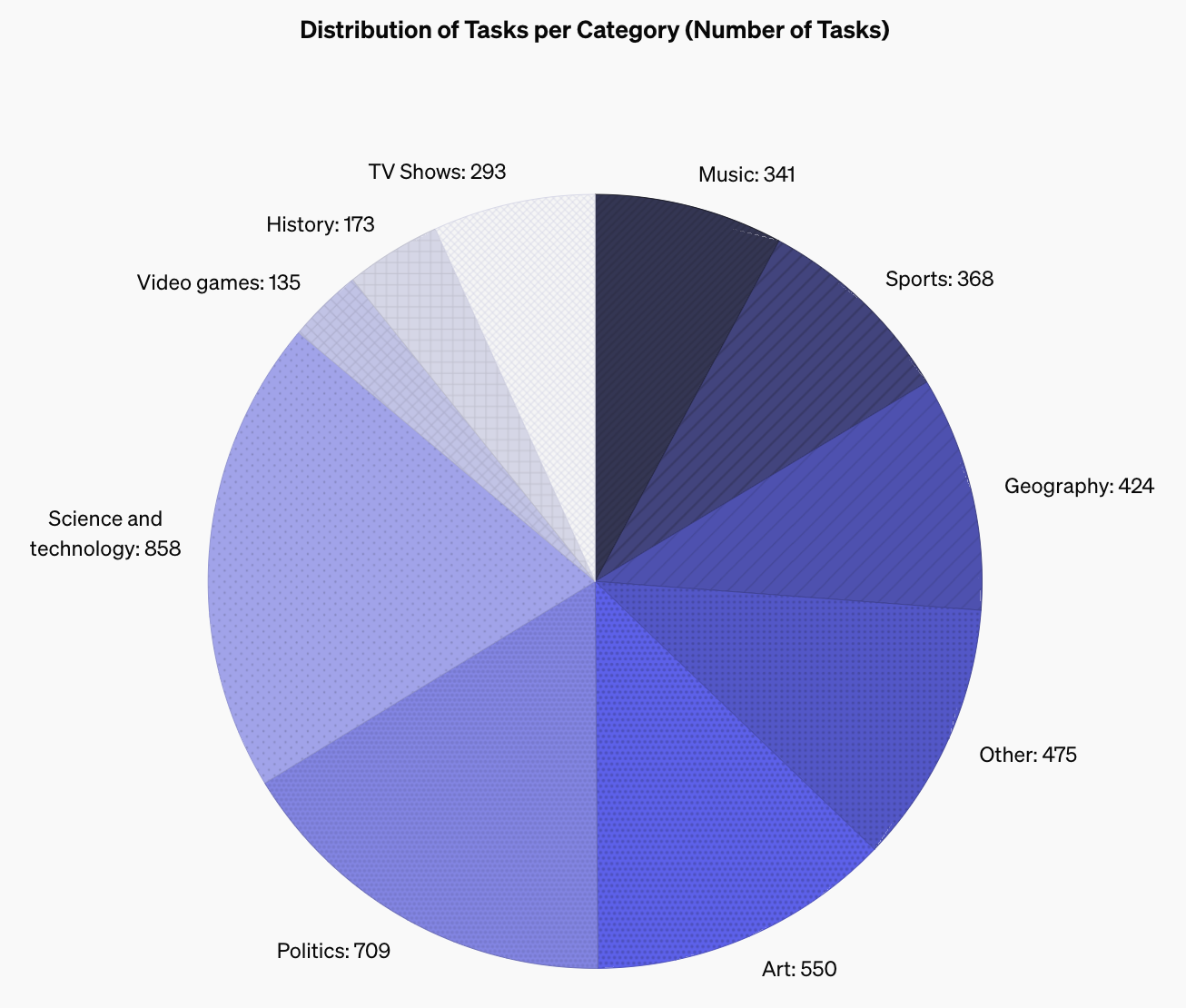
如上图所示,SimpleQA涵盖了广泛的知识领域,其中:
- 科学技术类占比最高(20%)
- 政治类次之(16.4%)
- 艺术类占12.7%
- 其他领域(如地理、体育等)分布相对均匀
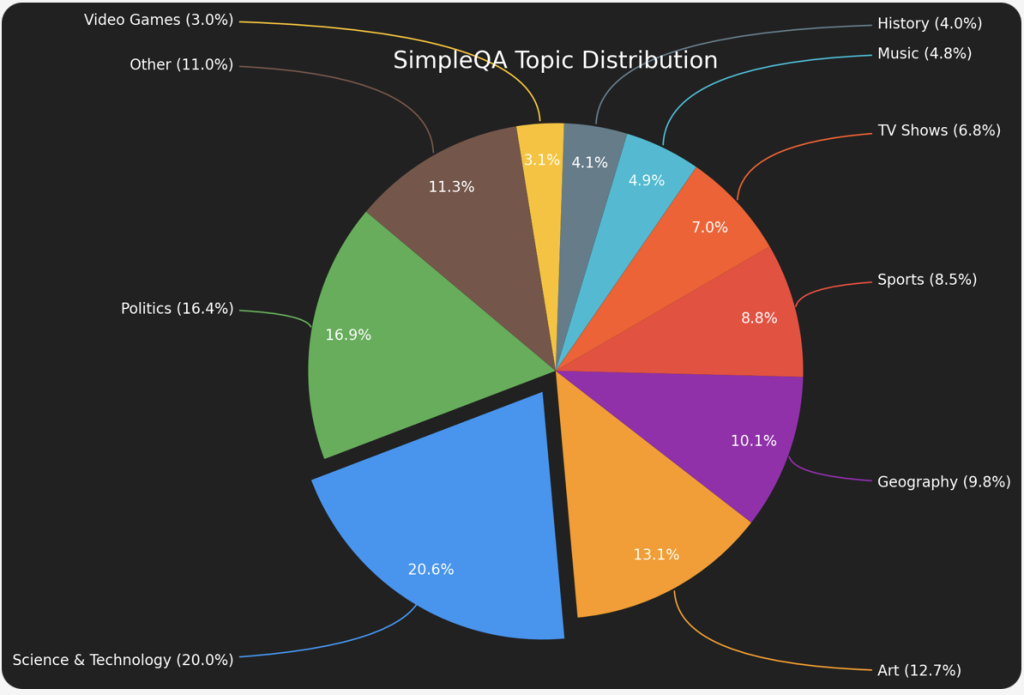
2.2 答案类型分布
根据统计分析:
- 日期类答案:32.8%
- 人名类答案:24.1%
- 数字类答案:15.3%
- 地点类答案:9.9%
- 其他类型:18.0%
3. 评估方法论
3.1 评分系统
采用三级评分机制:

- 正确(Correct)
- 错误(Incorrect)
- 未尝试(Not Attempted)
3.2 性能指标
主要评估指标包括:
- 整体正确率
- 尝试答题的正确率
- F-score(两者的调和平均)
4. 模型性能比较
如性能对比图所示,不同模型表现差异显著:
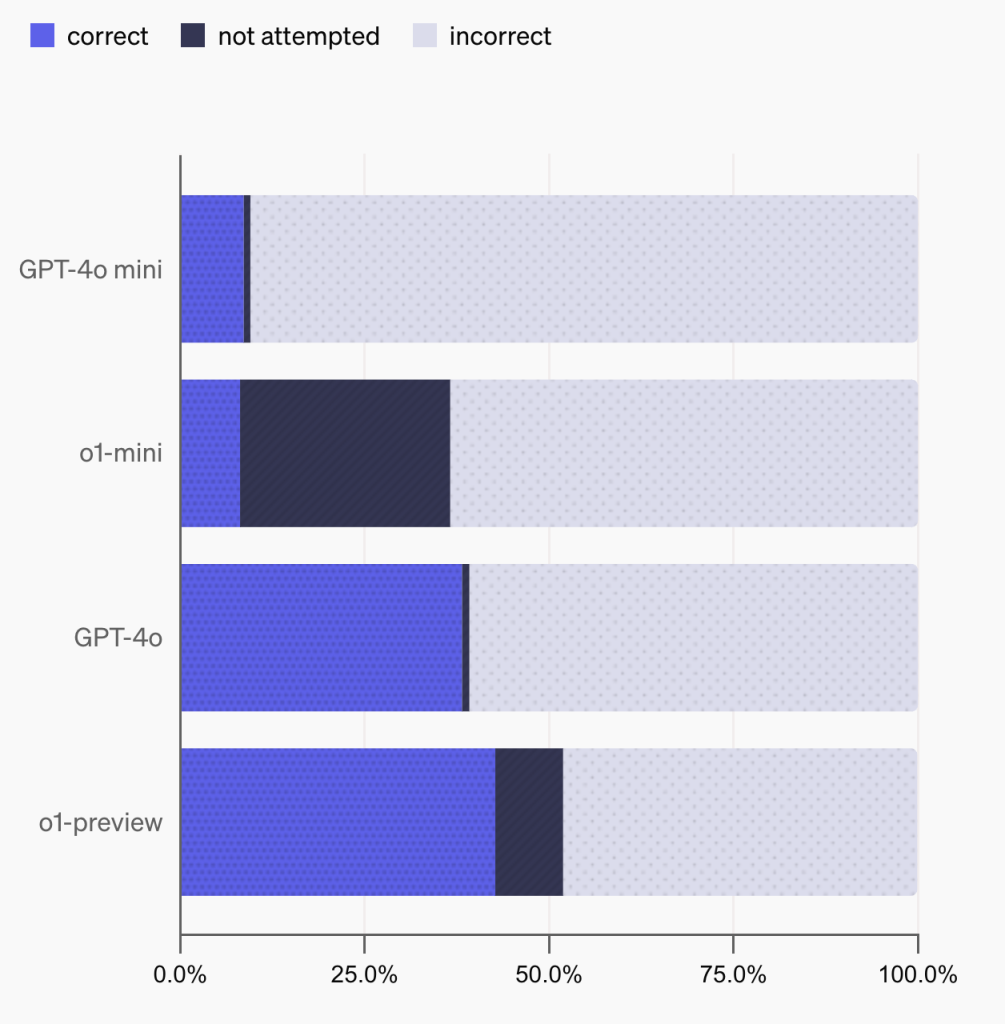
4.1 最佳表现
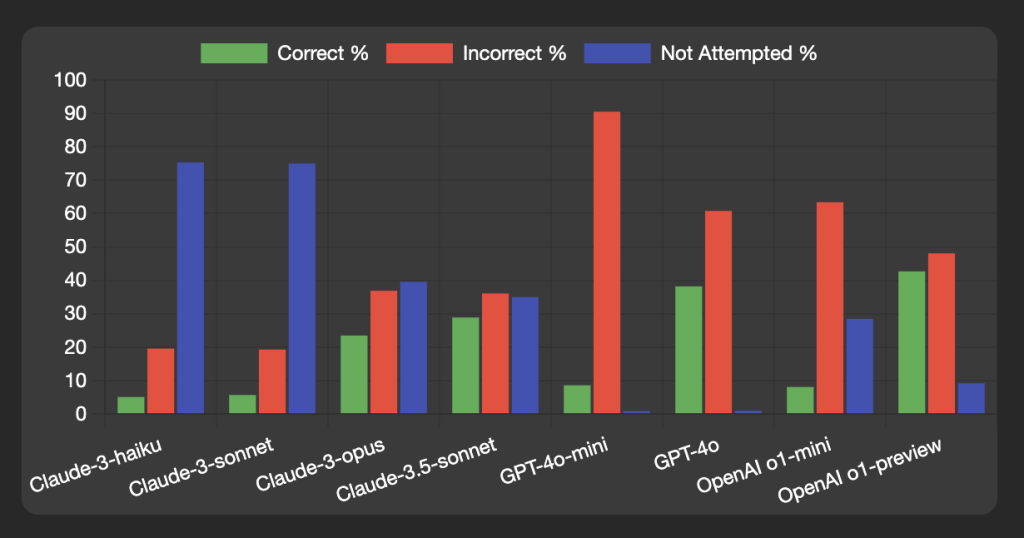
- OpenAI o1-preview: 42.7%正确率
- GPT-4o: 38.2%正确率
- Claude-3.5-sonnet: 28.9%正确率
4.2 模型特点分析
- 规模效应明显
- 大型模型普遍优于小型模型
- 模型参数量与性能呈正相关
- 策略差异
- Claude系列倾向保守,未尝试率较高
- GPT系列更倾向于尝试回答
5. 校准性研究
如校准曲线图所示:
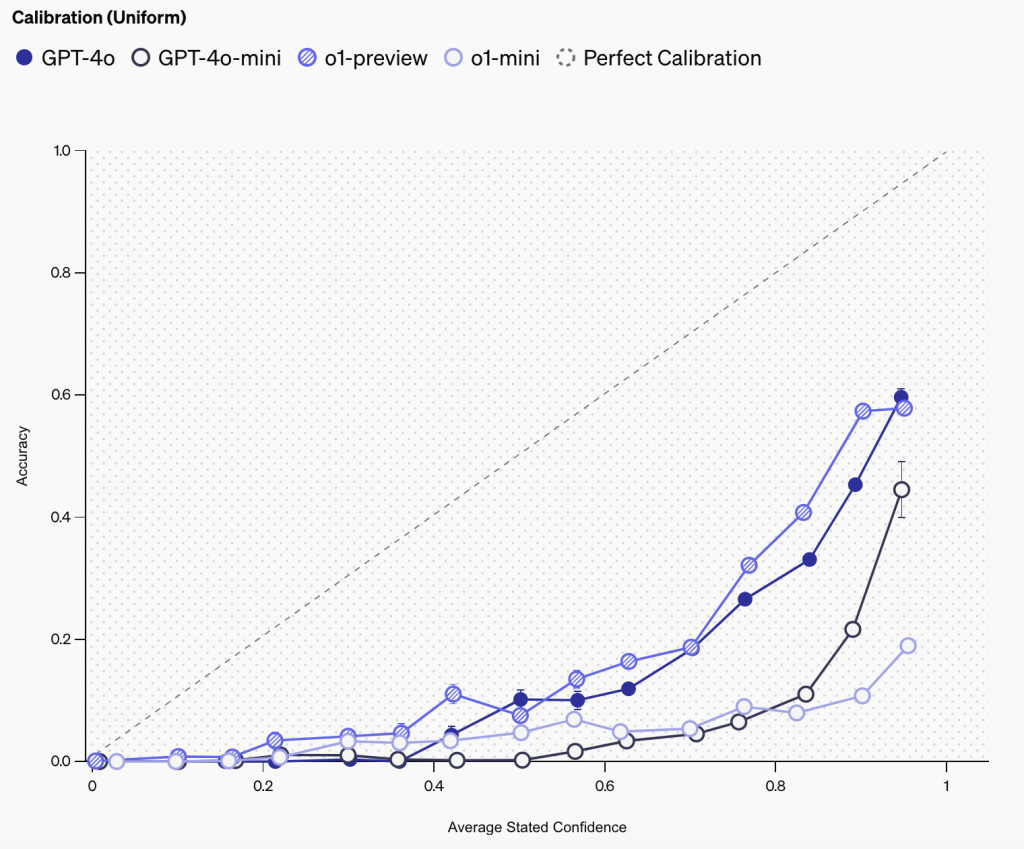
5.1 置信度分析
- o1-preview展现最佳校准性
- 所有模型都存在过度自信现象
- 大型模型校准性普遍优于小型模型
5.2 回答一致性
通过100次重复测试发现:
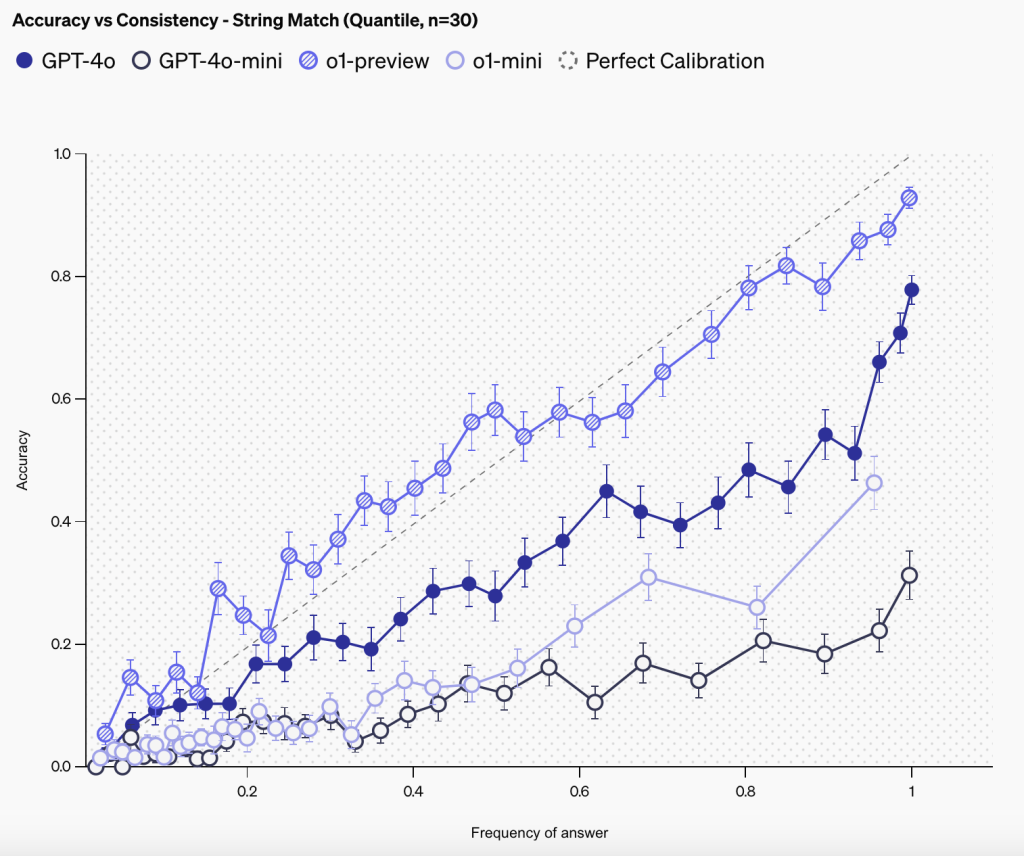
- 回答频率与准确性呈正相关
- 高频率答案更可能正确
流程图参考如下:
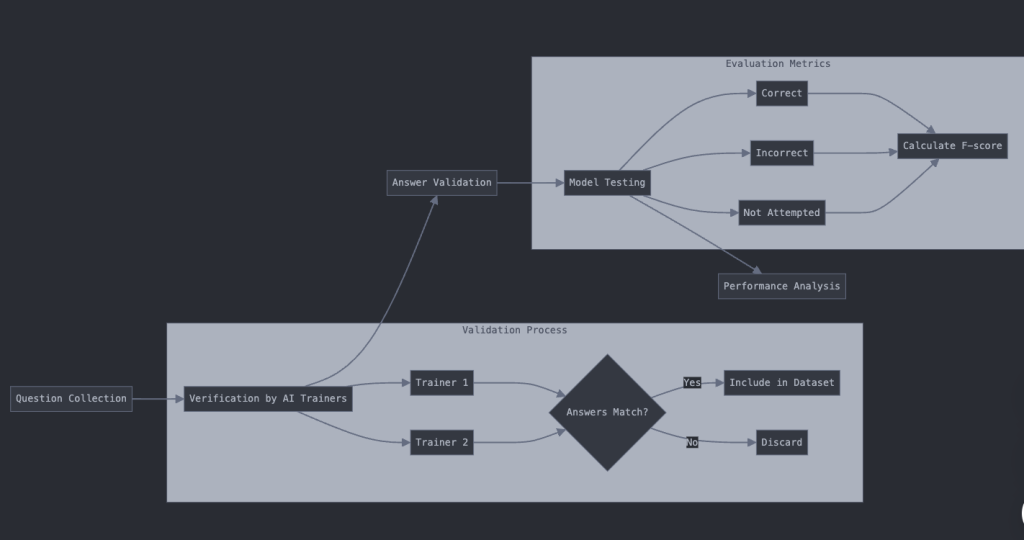
6. 技术优势与局限
6.1 优势
- 评估效率高
- 结果可复现
- 区分度良好
6.2 局限性
- 仅适用于短答案问题
- 可能需要定期更新数据集
- 难以评估复杂推理能力
7. 结论与展望
SimpleQA为评估大语言模型的事实性能力提供了一个标准化的框架。虽然存在一些局限性,但其简单、可靠的特点使其成为当前阶段评估模型事实性能力的重要工具。
未来的改进方向可能包括:
- 扩展问题类型
- 增加动态更新机制
- 建立跨语言版本
参考文献
- Wei, J., et al. (2024). Measuring short-form factuality in large language models. arXiv:2411.04368
- OpenAI. (2024). Introducing SimpleQA.
- Anthropic. (2024). Claude 3 Model Card.